应用背景 自动化测试使用过程中,发现很多App无法获取到控件、资源ID等内部资源,而目前主要的移动端自动化测试工具基本都是基于获取内部控件元素来进行操作。因此,传统的测试框架和工具无法满足项目组游戏自动化测试的需求。
Appium最新版本其实也集成了图像识别的元素定位方法find_element_by_image,但是需要安装依赖环境opencv4nodejs,使用方法如下:
1 2 3 self.driver.update_settings({"getMatchedImageResult" : True }) el = self.driver.find_element_by_image('path/to/img.ong' ) el.get_attribute('visual' )
但是该内置方法识别元素准确率较低,识别速度慢。这种情况下,只能通过点击坐标代替控件操作,而如何自动获取控件坐标就成了能否实现自动化的关键。解决的方法是将开源计算机视觉库OpenCV引入Appium框架,将按钮或控件的截图作为参数输入,在屏幕中通过图像特征识别获取对应控件坐标,调用AppiumAPI实现坐标点击,然后再次调用OpenCV图像识别库,自动判断操作结果,完成自动化测试。
OpenCV OpenCV的全称是:Open Source Computer Vision Library(开源计算机视觉库),其可以运行在Linux、Windows和Mac OS操作系统上。OpenCV轻量级而且高效的实现了图像处理和计算机视觉方面的很多通用算法,算法实现由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLA等语言的接口。
特征简介 特征就是有意义的图像区域,该区域具有独特性或易于识别性。角点与高密度区域是一个很好的特征,边缘可以将图像分为两个区域,因此可以看作很好的特征,斑点(与周围有很大区别的图像区域)也是有意义的特征。
特征检测(Feature detection)是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征检测的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。
在计算机视觉领域,兴趣点(也称关键点或特征点)的概念已经得到了广泛的应用, 包括目标识别、 图像配准、 视觉跟踪、 三维重建等。 这个概念的原理是, 从图像中选取某些特征点并对图像进行局部分析,而非观察整幅图像。 只要图像中有足够多可检测的兴趣点,并且这些兴趣点各不相同且特征稳定, 能被精确地定位,上述方法就十分有效。
特征匹配 匹配模式
暴力(Brute-Force)匹配:一种描述符匹配算法,该方法会比较两个描述符,并产生匹配结果列表,第一个描述符的所有特征都拿来和第二个进行比较。
K-最近邻(knn)匹配:在所有的机器学习算法中,knn可能是最简单的。
FLANN匹配:FLANN具有一种内部机制,该机制可以根据数据本身选取合适的算法来处理数据集,FLANN比其他的最近邻搜索快10倍。FLANN的单应性匹配,单应性指的是两幅图像中的一幅出现投影畸变时,他们还能彼此匹配。
SIFT SIFT的全称是Scale Invariant Feature Transform,尺度不变特征变换,由加拿大教授David G.Lowe提出的。是在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出、不会因光照、仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。SIFT特征对旋转、尺度缩放、亮度变化等保持不变性,是一种非常稳定的局部特征。
特征检测的视觉不变性是一个非常重要的概念。 但是要解决尺度不变性问题,难度相当大。 为解决这一问题,计算机视觉界引入了尺度不变特征 的概念。 它的理念是, 不仅在任何尺度下拍摄的物体都能检测到一致的关键点,而且每个被检测的特征点都对应一个尺度因子。 理想情况下,对于两幅图像中不同尺度的的同一个物体点, 计算得到的两个尺度因子之间的比率应该等于图像尺度的比率。
SIFT(Scale Invariant Feature Transform),尺度不变特征变换。SIFT特征对旋转、尺度缩放、亮度变化等保持不变性,是一种非常稳定的局部特征。
匹配阈值 为了排除因为图像遮挡和背景混乱而产生的无匹配关系的关键点,SIFT的作者Lowe提出了比较最近邻距离与次近邻距离的SIFT匹配方式:取一幅图像中的一个SIFT关键点,并找出其与另一幅图像中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离得到的比率ratio少于某个阈值T,则接受这一对匹配点。
因为对于错误匹配,由于特征空间的高维性,相似的距离可能有大量其他的错误匹配,从而它的ratio值比较高。显然降低这个比例阈值T,SIFT匹配点数目会减少,但更加稳定,反之亦然。
Lowe推荐ratio的阈值为0.8,但作者对大量任意存在尺度、旋转和亮度变化的两幅图片进行匹配,结果表明ratio取值在0. 4~0. 6 之间最佳,小于0. 4的很少有匹配点,大于0. 6的则存在大量错误匹配点,所以建议ratio的取值原则如下:
ratio=0.4:对于准确度要求高的匹配;ratio=0.6:对于匹配点数目要求比较多的匹配;ratio=0.5:一般情况下。
SURF Speeded Up Robust Features。加速版的SIFT。
SURF的流程和SIFT比较类似,这些改进体现在以下几个方面:
特征点检测是基于Hessian矩阵,依据Hessian矩阵行列式的极值来定位特征点的位置。并且将Hession特征计算与高斯平滑结合在一起,两个操作通过近似处理得到一个核模板。box filter与源图像卷积,而不是使用DoG算子。SURF使用一阶Haar小波在x、y两个方向的响应作为构建特征向量的分布信息。
ORB ORB是ORiented Brief的简称,是brief算法的改进版。ORB算法比SIFT算法快100倍,比SURF算法快10倍。在计算机视觉领域有种说法,ORB算法的综合性能在各种测评里较其他特征提取算法是最好的。
ORB算法是brief算法的改进,那么我们先说一下brief算法有什么缺点。BRIEF的优点在于其速度,其缺点是:
FAST FAST(加速分割测试获得特征, Features from Accelerated Segment Test) 。 这种算子专门用来快速检测兴趣点, 只需要对比几个像素,就可以判断是否为关键点。
跟Harris检测器的情况一样, FAST算法源于对构成角点的定义。FAST对角点的定义基于候选特征点周围的图像强度值。 以某个点为中心作一个圆, 根据圆上的像素值判断该点是否为关键点。 如果存在这样一段圆弧, 它的连续长度超过周长的3/4, 并且它上面所有像素的强度值都与圆心的强度值明显不同(全部更黑或更亮) , 那么就认定这是一个关键点。
用这个算法检测兴趣点的速度非常快, 因此十分适合需要优先考虑速度的应用。 这些应用包括实时视觉跟踪、 目标识别等, 它们需要在实
Harris角点 在图像中搜索有价值的特征点时,使用角点是一种不错的方法。 角点是很容易在图像中定位的局部特征, 并且大量存在于人造物体中(例如墙壁、 门、 窗户、 桌子等产生的角点)。
角点的价值在于它是两条边缘线的接合点, 是一种二维特征,可以被精确地定位(即使是子像素级精度)。 与此相反的是位于均匀区域或物体轮廓上的点以及在同一物体的不同图像上很难重复精确定位的点。 Harris特征检测是检测角点的经典方法。
opencv-python特征匹配 运行环境
Mac OS 10.14.6
Python 3.7
opencv-python-4.5.1
Opencv-Python安装可以使用如下命令
1 pip3 install opencv-python
关键点 OpenCV实现的特征检测接口包括detect()、compute()和detectAndCompute()函数,分别实现特征检测、特征描述,以及检测并描述一步到位。
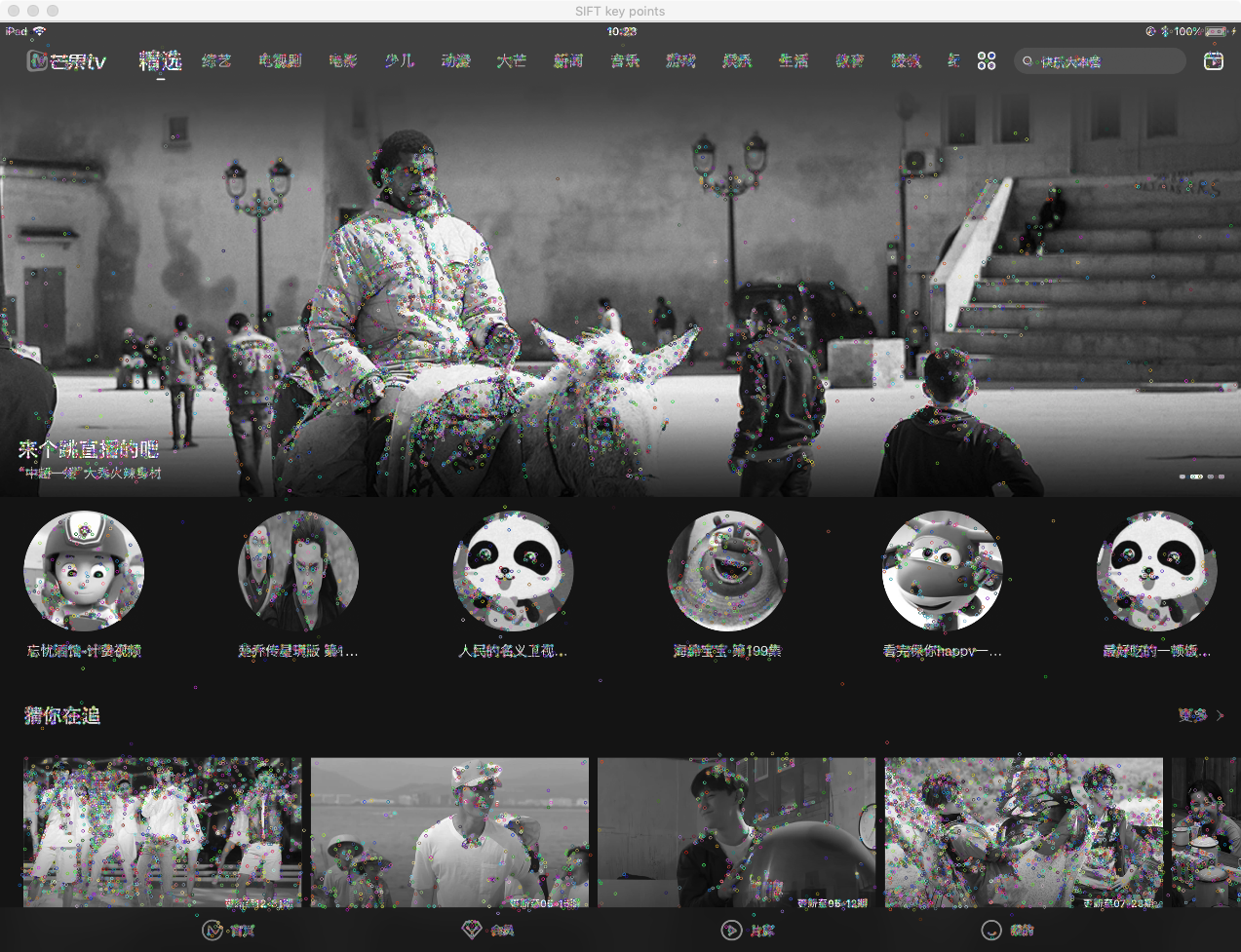
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import numpy as npimport cv2 as cvimport matplotlib.pyplot as pltimport pprintimport osimg1 = cv.imread('img/vip_tab.PNG' ,cv.IMREAD_GRAYSCALE) img2 = cv.imread('img/ipad_index.PNG' ,cv.IMREAD_GRAYSCALE) sift = cv.SIFT_create() kp1, des1 = sift.detectAndCompute(img1,None ) kp2, des2 = sift.detectAndCompute(img2,None ) img=cv.drawKeypoints(img2,kp2,img2) cv.imshow('SIFT key points' ,img) cv.imwrite('sift_keypoint.jpg' ,img) cv.waitKey()
运行之后可以看到绘制的特征点详情如下图所示:
特征匹配 Brute Force匹配和FLANN匹配是Opencv二维特征点匹配常见的两种办法,分别对应BFMatcher(BruteForceMatcher)和FlannBasedMatcher
二者的区别在于BFMatcher总是尝试所有可能的匹配,从而使得它总能够找到最佳匹配,这也是Brute Force(暴力法)的原始含义。而FlannBasedMatcher中FLANN的含义是Fast Library forApproximate NearestNeighbors,从字面意思可知它是一种近似法,算法更快但是找到的是最近邻近似匹配。
所以当我们需要找到一个相对好的匹配但是不需要最佳匹配的时候往往使用FlannBasedMatcher。当然也可以通过调整FlannBasedMatcher的参数来提高匹配的精度或者提高算法速度,但是相应地算法速度或者算法精度会受到影响。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # FLANN 匹配算法参数 FLANN_INDEX_KDTREE = 1 index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5) #第一个参数指定算法 search_params = dict(checks=50) #指定应递归遍历索引中的树的次数 # flann特征匹配 flann = cv.FlannBasedMatcher(index_params,search_params) matches = flann.knnMatch(des1,des2,k=2) # 初始化匹配模板表 matchesMask = [[0,0] for i in range(len(matches))] good=[] # 匹配阈值 for i,(m,n) in enumerate(matches): if m.distance < 0.5*n.distance: good.append(m) matchesMask[i]=[1,0]
对于基于FLANN的匹配器,我们需要传递两个字典,这些字典指定要使用的算法,其相关参数等。第一个是IndexParams,表示指定的算法。第二个字典是SearchParams,它指定了索引里的树应该被递归遍历的次数。更高的值带来更高的准确率。但是也花更多时间,如果你想改变值,search_params = dict(checks=100)
矩阵变换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 MIN_MATCH_COUNT=10 if len (good)>MIN_MATCH_COUNT: src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1 ,1 ,2 ) dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1 ,1 ,2 ) M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC,5.0 ) matchesMask = mask.ravel().tolist() h,w = img1.shape pts = np.float32([ [0 ,0 ],[0 ,h-1 ],[w-1 ,h-1 ],[w-1 ,0 ] ]).reshape(-1 ,1 ,2 ) dst = cv.perspectiveTransform(pts,M) cordinate_x1=get_Middle_Str(str (dst[2 ]),'[[' ,']]' ).split()[0 ].split('.' )[0 ] cordinate_y1=get_Middle_Str(str (dst[2 ]),'[[' ,']]' ).split()[1 ].split('.' )[0 ] cordinate_x2 = get_Middle_Str(str (dst[0 ]), '[[' , ']]' ).split()[0 ].split('.' )[0 ] cordinate_y2 = get_Middle_Str(str (dst[0 ]), '[[' , ']]' ).split()[1 ].split('.' )[0 ] mid_cordinate_x=(int (cordinate_x1)-int (cordinate_x2))/2 +int (cordinate_x2) mid_cordinate_y=(int (cordinate_y1)-int (cordinate_y2))/2 +int (cordinate_y2) print (mid_cordinate_x,mid_cordinate_y) img2 = cv.polylines(img2,[np.int32(dst)],True ,255 ,10 , cv.LINE_AA) else : print ( "Not enough matches are found - {}/{}" .format (len (good), MIN_MATCH_COUNT) ) matchesMask = None draw_params = dict (matchColor=(0 , 255 , 0 ), singlePointColor=None , matchesMask=matchesMask, flags=2 ) img3 = cv.drawMatches(img1, kp1, img2, kp2, good, None , **draw_params) plt.imshow(img3, 'gray' ), plt.show()
运行之后可以看到匹配的轮廓图,同时可以计算匹配的中心点坐标。
最后我们将整个过程封装成一个方法即可,方便在自动化项目中接入调试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 import numpy as npimport cv2 as cvimport matplotlib.pyplot as pltdef get_Middle_Str (content, startStr, endStr ): """ 根据字符串首尾字符来获取指定字符 :param content: 字符内容 :param startStr: 开始字符 :param endStr: 结束字符 :return: """ startIndex = content.index(startStr) if startIndex >= 0 : startIndex += len (startStr) endIndex = content.index(endStr) return content[startIndex:endIndex] def get_image_element_point (src_path,dst_path ): """ 获取图像目标的坐标点 :param src_path: 原图像 :param dst_path: 目标识别图像 :return: 目标元素的中心坐标点 """ print ('src_path:%s,dst_path:%s' %(src_path,dst_path)) src_img = cv.imread(src_path,cv.IMREAD_GRAYSCALE) dst_img = cv.imread(dst_path,cv.IMREAD_GRAYSCALE) sift = cv.SIFT_create() kp1, des1 = sift.detectAndCompute(src_img,None ) kp2, des2 = sift.detectAndCompute(dst_img,None ) FLANN_INDEX_KDTREE = 1 index_params = dict (algorithm = FLANN_INDEX_KDTREE, trees = 5 ) search_params = dict (checks=50 ) flann = cv.FlannBasedMatcher(index_params,search_params) matches = flann.knnMatch(des1,des2,k=2 ) matchesMask = [[0 ,0 ] for i in range (len (matches))] good=[] for i,(m,n) in enumerate (matches): if m.distance < 0.5 *n.distance: good.append(m) matchesMask[i]=[1 ,0 ] MIN_MATCH_COUNT=10 if len (good)>MIN_MATCH_COUNT: src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1 ,1 ,2 ) dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1 ,1 ,2 ) M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC,5.0 ) matchesMask = mask.ravel().tolist() h,w = src_img.shape pts = np.float32([ [0 ,0 ],[0 ,h-1 ],[w-1 ,h-1 ],[w-1 ,0 ] ]).reshape(-1 ,1 ,2 ) dst = cv.perspectiveTransform(pts,M) cordinate_x1=get_Middle_Str(str (dst[2 ]),'[[' ,']]' ).split()[0 ].split('.' )[0 ] cordinate_y1=get_Middle_Str(str (dst[2 ]),'[[' ,']]' ).split()[1 ].split('.' )[0 ] cordinate_x2 = get_Middle_Str(str (dst[0 ]), '[[' , ']]' ).split()[0 ].split('.' )[0 ] cordinate_y2 = get_Middle_Str(str (dst[0 ]), '[[' , ']]' ).split()[1 ].split('.' )[0 ] mid_cordinate_x=(int (cordinate_x1)-int (cordinate_x2))/2 +int (cordinate_x2) mid_cordinate_y=(int (cordinate_y1)-int (cordinate_y2))/2 +int (cordinate_y2) img2 = cv.polylines(dst_img,[np.int32(dst)],True ,255 ,10 , cv.LINE_AA) draw_params = dict (matchColor=(0 , 255 , 0 ), singlePointColor=None , matchesMask=matchesMask, flags=2 ) img3 = cv.drawMatches(src_img, kp1, dst_img, kp2, good, None , **draw_params) plt.imshow(img3, 'gray' ), plt.show() return int (mid_cordinate_x/2 ),int (mid_cordinate_y/2 ) else : print ( "Not enough matches are found - {}/{}" .format (len (good), MIN_MATCH_COUNT) ) matchesMask = None if __name__ == '__main__' : img1 = './img/login_btn.PNG' img2 = './img/dst_image.PNG' get_image_element_point(img1,img2)
接入自动化 Appium+python 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from appium import webdriverfrom flann_match import get_image_element_pointdef appium_desired (): '''启动App配置驱动信息''' desired_caps={} desired_caps['udid' ]=data['udid' ] desired_caps['deviceName' ]=data['deviceName' ] desired_caps['platformName' ] =data['platformName' ] desired_caps['platformVersion' ] =data['platformVersion' ] desired_caps['bundleId' ]=data['bundleId' ] try : logging.info('初始化driver' ) driver=webdriver.Remote('http://127.0.0.1:4723/wd/hub' ,desired_caps) sleep(6 ) driver.get_screenshot_as_file('/Users/atx/Desktop/at-iphone-youliao/img/ipad_index.PNG' ) img1='../img/vip_tab.PNG' img2='../img/ipad_index.PNG' x,y=get_image_element_point(img1,img2) sleep(3 ) TouchAction(driver).tap(x=x, y=y).perform() driver.implicitly_wait(30 ) return driver except BaseException as msg: logging.info('driver初始化失败,失败原因:%s' %msg) if __name__ == '__main__' : driver=appium_desired()
RF+Appium 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 *** Settings *** Library ../image_match.py ${img_root_path} xxxxx ${hide_keoard} xxxxx.PNG ${dst_path} xxxxxx.PNG *** Keywords *** 公共-图像匹配坐标 [Arguments] ${src_path} ${dst_path} ${x} ${y}= get_image_element_point ${src_path} ${dst_path} [Return] ${x} ${y} 公共-隐藏键盘 capture page screenshot ${img_root_path}dst_image.PNG sleep 2 ${x} ${y}= 公共-图像匹配坐标 ${hide_keoard} ${dst_path} sleep 2 click a point ${x} ${y}
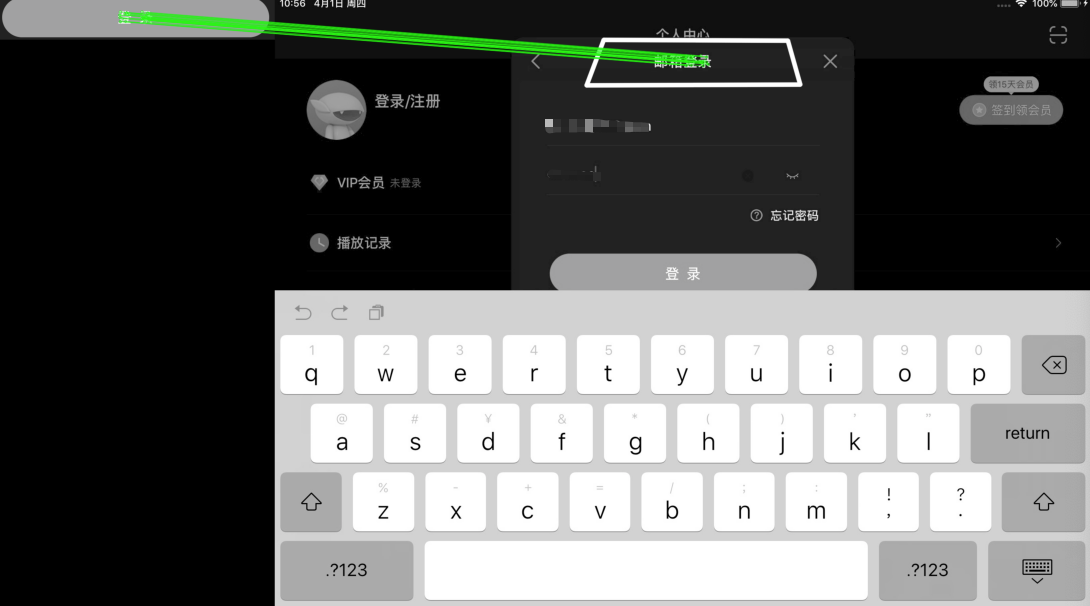
小结 虽然Opencv图像识别功能非常强大,但是也存在不足之处,比如识别的图片在被识别的图像中有多个相同元素时会无法准确识别到期望的目标,如下图所示,期望匹配是登录界面的“登录”按钮,但是却识别到“邮箱登录”的标题位置了。
对于这种情况我们可能需要进行模型训练来提高识别的准确度。
参考资料